Lots of people think they know something about SEO, which is cool. Every webmaster on the planet should know something about it, just so they’re doing the basic things, such as performing keyword research, filling in their Meta data for every page on their sites, and getting backlinks. Simple 101 stuff. But then, there are the techniques that are slightly advanced and lots of webmasters get them wrong. Take the rel=”canonical” tag, for example, which is recognized by all the major search engines.
WordPress SEO by Yoast
This tag should be used in your header information to indicate that if there are duplicate pages on your website, you want Google to know which is the right page. Asking them to index 2 identical pages without regard to which is the “control” page or dominant page could spell trouble for your site. Having two pages with the same content with little variation (such as a headline when you’re running a split test) should have rel=”canonical” involved.
But… There are times when you might use rel=”canonical” in the wrong way.
I just read a great article over at the Google Webmaster Central blog about this, and you should read it, too, if you’re the least bit techy. If not, let me put some of that into terms anyone can understand.
First, here’s what a rel=”canonical” tag should be like:
Let’s say you’re running an A/B split test and you want your control page to be the dominant, at least until you see which page wins in the test. Here’s what the tag should look like on that dominant page and on the test page:
<link rel=”canonical” href=”http://www.domain.com/page.html/”>
On the control page, the URL would be its own link. On the test page, the URL would be the control page link.
Simple enough, right?
Google also says:
“The rel=canonical link consolidates indexing properties from the duplicates, like their inbound links, as well as specifies which URL you’d like displayed in search results.
Well… There are some situations where webmasters can be confused. Here are five places that the Google article mentioned:
- If you have an article that spans three web pages, you shouldn’t declare that page 1 is the canonical, except on that page. Each of those article pages is unique and if you make page 1 canonical and repeat that same link on page 2 and page 3, pages 2 and 3 may never be indexed. You want all of the pages indexed!
- The canonical version of a page should be very similar to the other page that you’re telling search engines to ignore.
- Be sure that the canonical version of the page actually exists. So, if you are running a test and you have the control page as the canonical page, but the test page wins. Shift the canonical to the winning page, which then becomes control. Then, add a new canonical tag to the next test page for the new control. Otherwise, the losing control page will continue to be the indexed version in search. Or, if you deleted it, the canonical link will be broken. This is VERY important to get the proper search results.
- Make sure that the page that rel=canonical applies to doesn’t have a no index, no follow robots tag and that it’s not excluded in robots.txt. Robots.txt is a file that tells search spiders where they aren’t allowed to go on your site. Having a canonical page be one that you’re telling search spiders to stay away from isn’t a good idea.
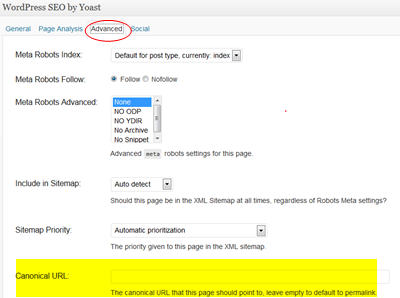
- You should include the rel=canonical tag in the section of your HTML page, or in the case of WordPress, you can set a canonical URL using WordPress SEO by Yoast. It’s in the “Advanced” tab of the section on your page where that plugin allows you to write titles and descriptions for each post you make.
- If you specify more than one rel=canonical, spiders will pick one and ignore the rest. Only ONE tag should be set.
Doing any of the above is tantamount to shooting yourself in the foot. If you’re adventurous, I encourage you to read the article. Or, if you have questions, just let me know what they are below. Happy to help!



I am currently using Yoast WordPress SEO plugin v1.4.18. Google Webmaster Tools is reporting several posts with duplicate title and description. All these posts are multipage posts. Upon digging deeper I found that the Canonical URL output by the plugin may be incorrect. For example, If I have a single post split into 3 pages (because it is extremely lengthy) then on the 2nd page of my post I see the following added by Yoast’s WordPress SEO plugin:
Sorry if I am wrong, but shouldn’t the Canonical URL point to the first page, which in this case should be:
When I disable WordPress SEO plugin, WordPress generates its own Canonical tag and that points to the first page.
Is this a bug in the plugin? Or is my understanding of Canonical URL wrong? I think that the duplicate Title and Description warnings I see in GWT is related to this. Again, thanks for the help.
Not sure if the HTML codes I pasted in my previous comments appeared.
Hi Linu,
I’m sorry, but no, the HTML didn’t come forth. But… Here’s what I get from you:
You have one article that is long and you split it into three posts, which is fine.
What should happen is that each post (which are separate pages and search engines rank pages, not sites or multiple-page posts as one) should have its own unique title and description. Don’t duplicate tags either because each page is different, even though it’s part of the same article. I mean, if you want to write the same description, just paraphrase with different words, but never use the same title. Use Part 1, 2, 3 at the beginning, for example.
The canonical should be the first page of your article and the other two parts “no-indexed,” as you don’t really want all three pages indexed. Imagine if someone ran across page 3 in Google and had to figure out that it was a 3-part post and backtrack. Since customer experience is so very important these days, wanting all three pages indexed could hurt rather than help, right?
Hope that helps. Let me know if you need more explanation.
Pat
Hi Pat,
Very useful article, thanks.
Question: shouldn’t WordPress SEO automatically detect the main page in a split post (let’s say just using the nextpage tag) and create the rel=prev and rel=next for the others? So, in this case, all the content would be indexed with a defined first page as reference?
I mean, without writing anything in the canonical url space inside the advanced tab.
It should, but some themes apparently don’t play nice with the plugin as recent as last fall. I don’t generally use articles that span more than one page because people’s time is short and they have short attention spans, but… That said… You can set the canonical on the “advanced” tab. So, instead of a URL, just add “next” or “prev.” I’m not sure that it would occur naturally. If you don’t set the canonical, I’m guessing that all three or however many pages would have the specific page URL set by WPSEO as the canonical.
Try it, but be sure to check the source code to make sure it’s working properly.
Hi Pat, thanks for the answer.
Yes, if I don’t specific anything, each page is going to have its specific URL/2 or /3 as referer, but if I write “next” is going to place the main URL as referer. So, adding “next”, instead of the URL, should say to Google to index the content of all pages but keeping 1 as reference, right?. The problem, with very long articles, around 5000 for example, is that most of the content has to be indexed, and not only the first page. But it has to be indexed with keeping the main URL as reference.
Here’s what I’d like to achieve, from google webmasters: http://googlewebmastercentral.blogspot.it/2011/09/pagination-with-relnext-and-relprev.html
I didn’t know I could write “next” inside the canonical URL space, but is it going to automatically do what is written in the page above? How can I check that? Thanks
Hi David,
You’re welcome for the answer, but as I said, I’ve not tried splitting pages. Not sure that WPSEO will work properly for that, and yesterday before I answered you, I did a little research and it seemed that as of last fall, these sequence tags weren’t working. So… No guarantee. That said, WPSEO has had several updates since then.
But yes, using “next” and “previous” should get all of the content indexed. To check up on WPSEO, view the page source. You’ll see the rel=”canonical” or rel=”next,” etc. Somewhere before the closing tag. (In Chrome or FFox, you can click CTRL+F and search for rel=, too.)
The sad part is that if that doesn’t work, I’m not sure you can make it work in WordPress. There could be another plugin that will help, but then, plugins sometimes don’t play nice with one another. If nothing else, title the pages, “Part 1, Part 2, etc.” Then, they can each be canonical. That’s the only way around it that I can think of.
Hi Pat,
Yes, I’ve checked and there is rel=”next” and both rel=”next” and rel=”prev” if you have more pages. The only thing, if you have more pages is that from the second page and the others pages the first line will be rel=”canonical” href=”http://next”, instead of the the main canonical url for href! But that’s because we have written next in the canonical space. Then it will follow with the right links for rel=”next” and rel=”prev”. I think it’s ok like this. Thanks 🙂
Good! Glad to know it. Thanks for the discussion, David!
Best,
Pat
hi, i have a blog consists multiple subdomains, subdomains-pages(articles) with different url’s.
i have added canonical like this , please check weather it is correct or not.
Domain Page canonical :
Sub-Domain-1 Page canonical :
Sub-Domain-1 [Articles Page ] canonical :
Sub-Domain-2 Page canonical :
Sub-Domain-2 [Articles Page ] canonical :
and so on…..
I want to ask is this method of placing “canonical” is correct or not. If not then please make it correct
thanks.
Hi Sandy,
Every page in your site should be canonical, providing that they are indeed the original versions of each page.
If, however, your sub-domains are mirrors of the original domains, they should have canonicals pointing back to the original.
Only pages with original content should be canonical.
Does that help, Sandy?
Pat
I recently did a real world experiment to see the effects of changing canonical url’s across domains.
http://www.thesjg.com/2016/03/real-world-effects-changing-canonical-url/
It’s obviously a very strong signal to Google, and using it incorrectly would have disastrous consequences for your SEO.
Oh so true! Great study, Samuel! It’s nice to see concrete evidence. I know you’re right. I’ve done some testing myself, but corroboration is great. Thanks for sharing!